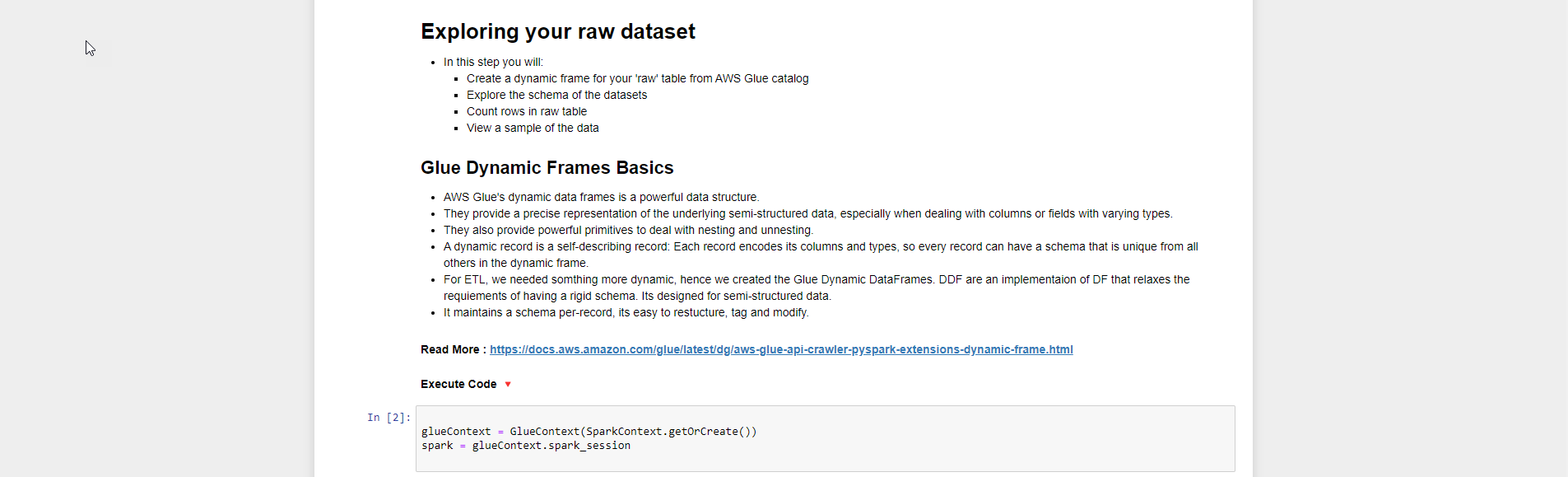
Create_Dynamic_Frame.from_Catalog
Create_Dynamic_Frame.from_Catalog - My issue is, if i use create_dynamic_frame_from_catalog (), it is running very slow, where as if i use create_sample_dynamic_frame_from_catalog () with max sample limit as 5 million, it is. I have a table in my aws glue data catalog called 'mytable'. When creating your dynamic frame, you may need to explicitly specify the connection name. I'm trying to create a dynamic glue dataframe from an athena table but i keep getting an empty data frame. I'd like to filter the resulting dynamicframe to. Try modifying your code to include the connection_type parameter: This document lists the options for improving the jdbc source query performance from aws glue dynamic frame by adding additional configuration parameters to the ‘from catalog’. Create_dynamic_frame_from_catalog(database, table_name, redshift_tmp_dir, transformation_ctx = , push_down_predicate= , additional_options = {}, catalog_id = none) returns a. Now, i try to create a dynamic dataframe with the from_catalog method in this way: From_catalog(frame, name_space, table_name, redshift_tmp_dir=, transformation_ctx=) writes a dynamicframe using the specified catalog database and table name. With three game modes (quick match, custom games, and single player) and rich customizations — including unlockable creative frames, special effects, and emotes — every. Now, i try to create a dynamic dataframe with the from_catalog method in this way: I have a table in my aws glue data catalog called 'mytable'. I have a mysql source from which i am creating a glue dynamic frame with predicate push down condition as follows. I'm trying to create a dynamic glue dataframe from an athena table but i keep getting an empty data frame. My issue is, if i use create_dynamic_frame_from_catalog (), it is running very slow, where as if i use create_sample_dynamic_frame_from_catalog () with max sample limit as 5 million, it is. Try modifying your code to include the connection_type parameter: This document lists the options for improving the jdbc source query performance from aws glue dynamic frame by adding additional configuration parameters to the ‘from catalog’. Create_dynamic_frame_from_catalog(database, table_name, redshift_tmp_dir, transformation_ctx = , push_down_predicate= , additional_options = {}, catalog_id = none) returns a. Leverage aws glue data catalog: Create_dynamic_frame_from_catalog(database, table_name, redshift_tmp_dir, transformation_ctx = , push_down_predicate= , additional_options = {}, catalog_id = none) returns a. With three game modes (quick match, custom games, and single player) and rich customizations — including unlockable creative frames, special effects, and emotes — every. I'd like to filter the resulting dynamicframe to. Try modifying your code to include the connection_type parameter: In this. Try modifying your code to include the connection_type parameter: When creating your dynamic frame, you may need to explicitly specify the connection name. I have a table in my aws glue data catalog called 'mytable'. With three game modes (quick match, custom games, and single player) and rich customizations — including unlockable creative frames, special effects, and emotes — every.. I'd like to filter the resulting dynamicframe to. In this article, we'll explore five best practices for using pyspark in aws glue and provide examples for each. I'm trying to create a dynamic glue dataframe from an athena table but i keep getting an empty data frame. Try modifying your code to include the connection_type parameter: # read from the. When creating your dynamic frame, you may need to explicitly specify the connection name. The athena table is part of my glue data catalog. This document lists the options for improving the jdbc source query performance from aws glue dynamic frame by adding additional configuration parameters to the ‘from catalog’. I have a mysql source from which i am creating. # read from the customers table in the glue data catalog using a dynamic frame dynamicframecustomers = gluecontext.create_dynamic_frame.from_catalog(database =. Try modifying your code to include the connection_type parameter: When creating your dynamic frame, you may need to explicitly specify the connection name. The athena table is part of my glue data catalog. I'd like to filter the resulting dynamicframe to. I have a table in my aws glue data catalog called 'mytable'. # create a dynamicframe from a catalog table dynamic_frame = gluecontext.create_dynamic_frame.from_catalog(database = mydatabase, table_name =. In this article, we'll explore five best practices for using pyspark in aws glue and provide examples for each. From_catalog(frame, name_space, table_name, redshift_tmp_dir=, transformation_ctx=) writes a dynamicframe using the specified catalog database and. My issue is, if i use create_dynamic_frame_from_catalog (), it is running very slow, where as if i use create_sample_dynamic_frame_from_catalog () with max sample limit as 5 million, it is. The athena table is part of my glue data catalog. Dynamicframes can be converted to and from dataframes using.todf () and fromdf (). Leverage aws glue data catalog: When creating your. This document lists the options for improving the jdbc source query performance from aws glue dynamic frame by adding additional configuration parameters to the ‘from catalog’. I have a table in my aws glue data catalog called 'mytable'. # read from the customers table in the glue data catalog using a dynamic frame dynamicframecustomers = gluecontext.create_dynamic_frame.from_catalog(database =. From_catalog(frame, name_space, table_name,. My issue is, if i use create_dynamic_frame_from_catalog (), it is running very slow, where as if i use create_sample_dynamic_frame_from_catalog () with max sample limit as 5 million, it is. # create a dynamicframe from a catalog table dynamic_frame = gluecontext.create_dynamic_frame.from_catalog(database = mydatabase, table_name =. The athena table is part of my glue data catalog. Leverage aws glue data catalog: I'd. This document lists the options for improving the jdbc source query performance from aws glue dynamic frame by adding additional configuration parameters to the ‘from catalog’. From_catalog(frame, name_space, table_name, redshift_tmp_dir=, transformation_ctx=) writes a dynamicframe using the specified catalog database and table name. The athena table is part of my glue data catalog. Create_dynamic_frame_from_catalog(database, table_name, redshift_tmp_dir, transformation_ctx = , push_down_predicate= ,. My issue is, if i use create_dynamic_frame_from_catalog (), it is running very slow, where as if i use create_sample_dynamic_frame_from_catalog () with max sample limit as 5 million, it is. I have a mysql source from which i am creating a glue dynamic frame with predicate push down condition as follows. This document lists the options for improving the jdbc source query performance from aws glue dynamic frame by adding additional configuration parameters to the ‘from catalog’. Try modifying your code to include the connection_type parameter: I'd like to filter the resulting dynamicframe to. I'm trying to create a dynamic glue dataframe from an athena table but i keep getting an empty data frame. Now, i try to create a dynamic dataframe with the from_catalog method in this way: With three game modes (quick match, custom games, and single player) and rich customizations — including unlockable creative frames, special effects, and emotes — every. # create a dynamicframe from a catalog table dynamic_frame = gluecontext.create_dynamic_frame.from_catalog(database = mydatabase, table_name =. Use join to combine data from three dynamicframes from pyspark.context import sparkcontext from awsglue.context import gluecontext # create gluecontext sc =. From_catalog(frame, name_space, table_name, redshift_tmp_dir=, transformation_ctx=) writes a dynamicframe using the specified catalog database and table name. Dynamicframes can be converted to and from dataframes using.todf () and fromdf (). When creating your dynamic frame, you may need to explicitly specify the connection name. In this article, we'll explore five best practices for using pyspark in aws glue and provide examples for each. Leverage aws glue data catalog:
glueContext create_dynamic_frame_from_options exclude one file? r/aws
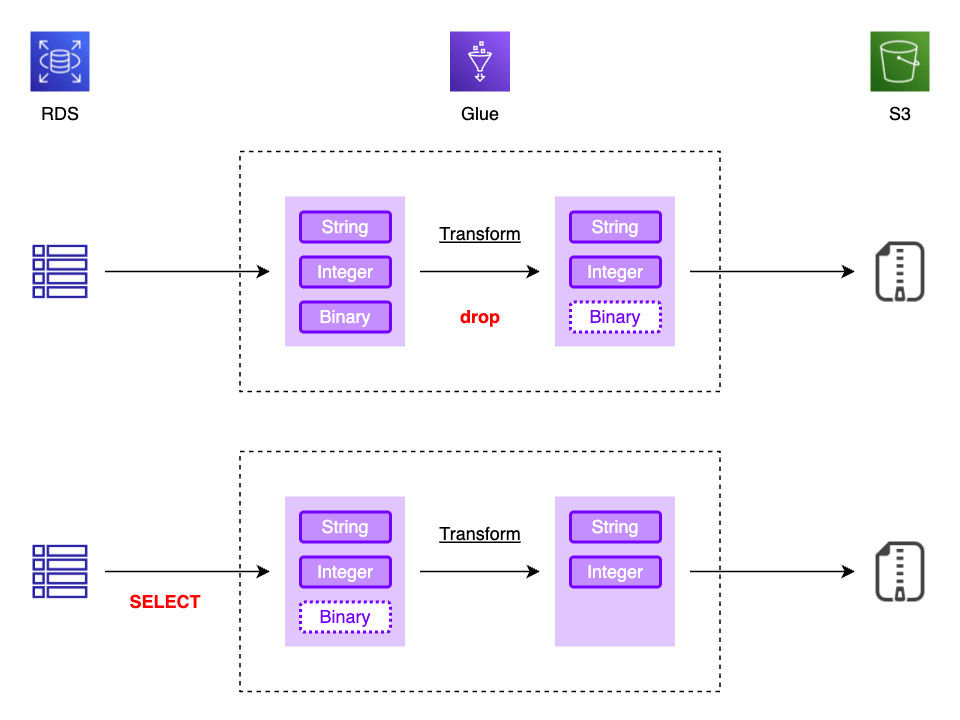
Glue DynamicFrame 生成時のカラム SELECT でパフォーマンス改善した話

AWS Glue create dynamic frame SQL & Hadoop
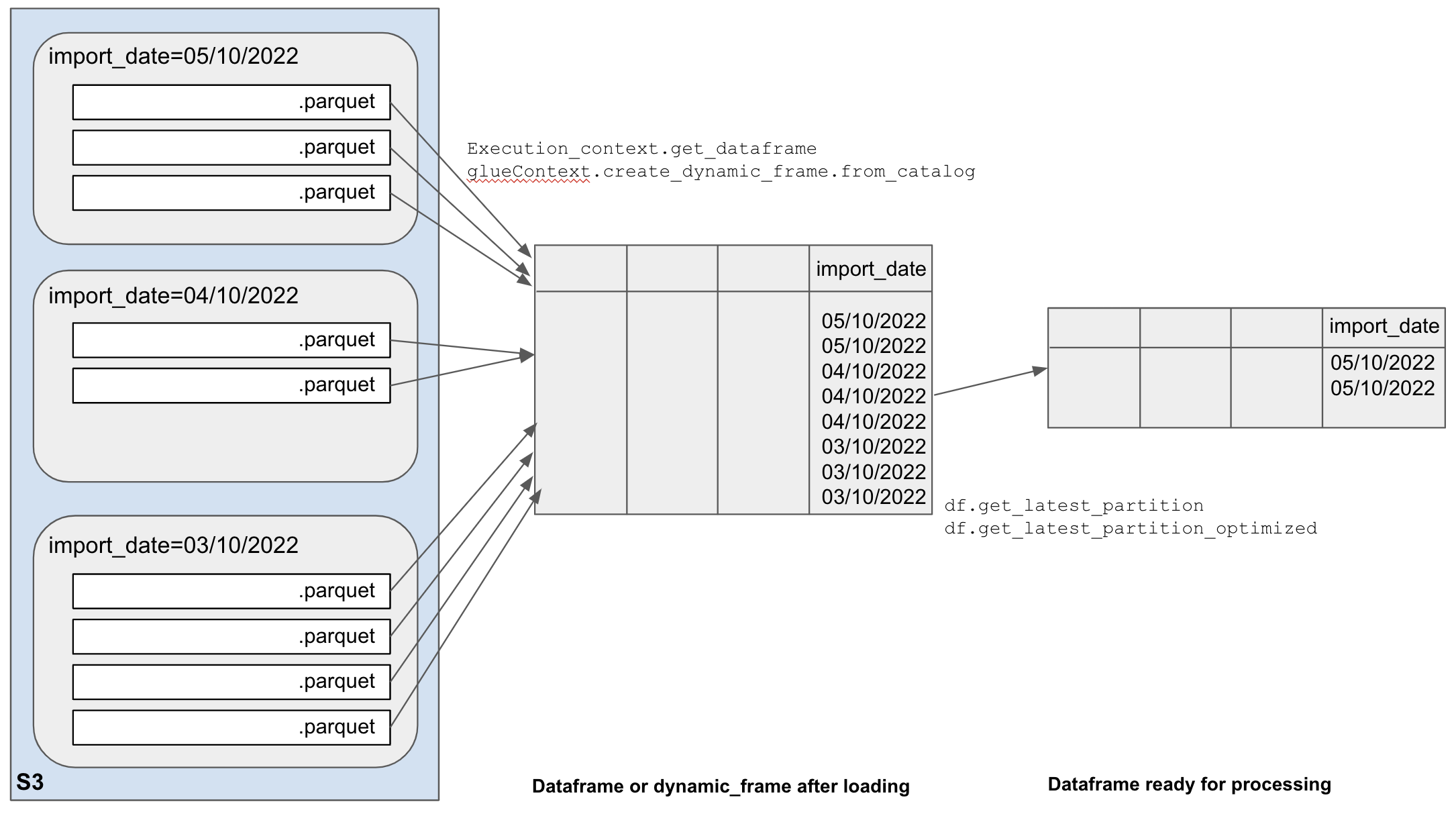
Optimizing Glue jobs Hackney Data Platform Playbook
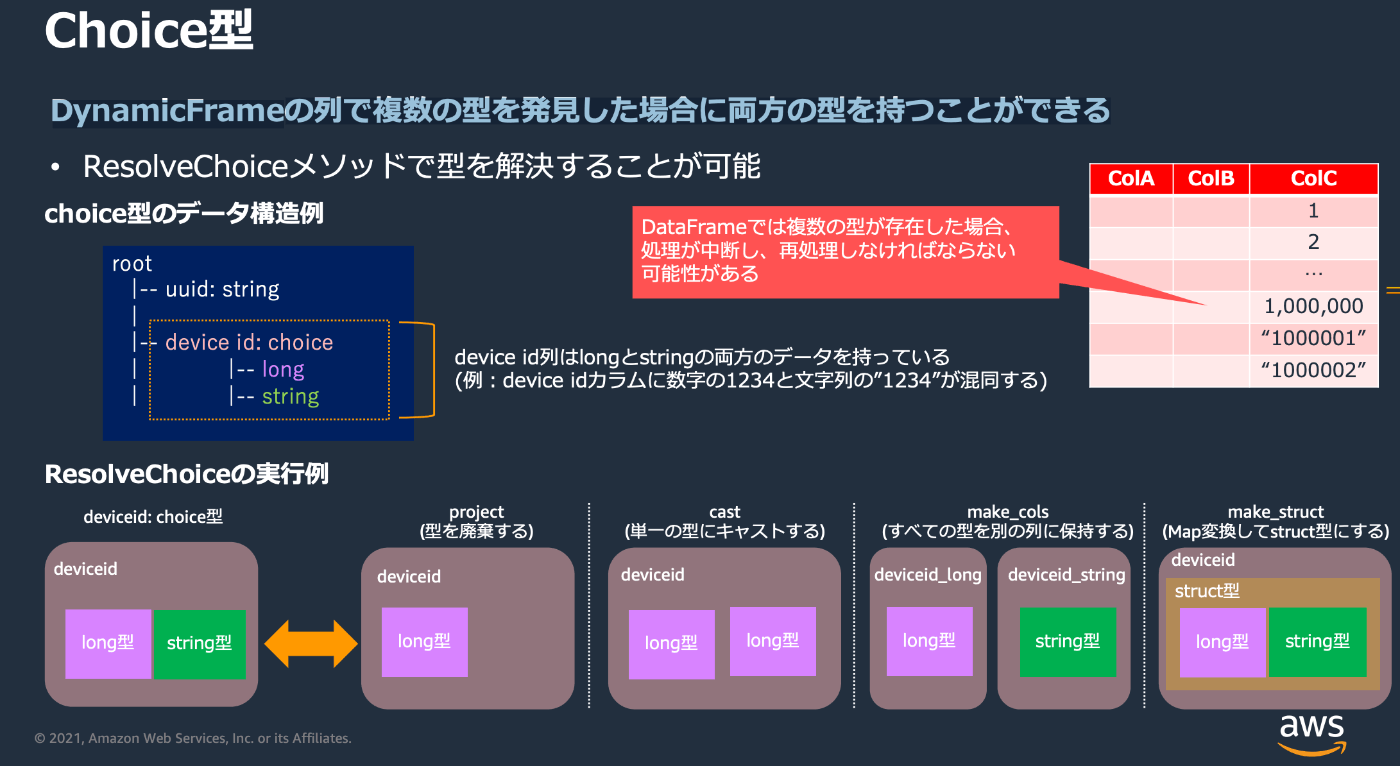
AWS Glueに入門してみた
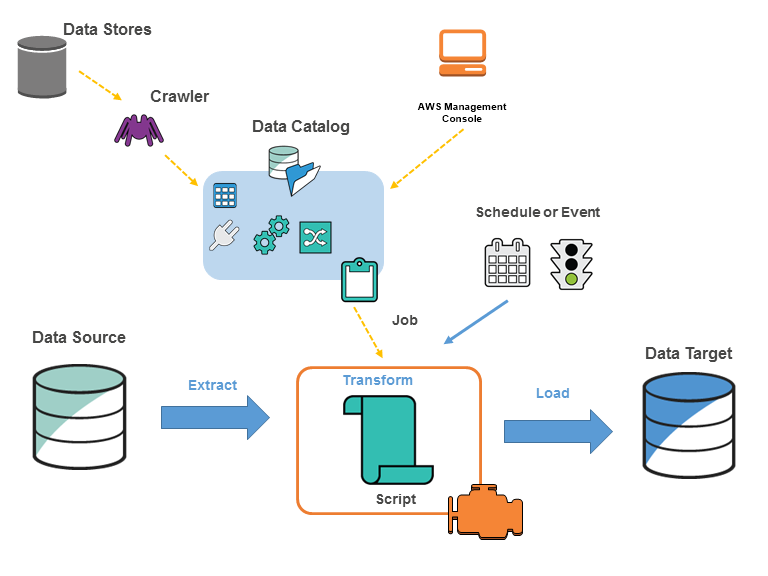
Dynamic Frames Archives Jayendra's Cloud Certification Blog
Chuyển đổi dữ liệu XÂY DỰNG DATALAKE VỚI DỮ LIỆU CỦA BẠN

🤩Day6 📍How to create Dynamic Frame Webpage 🏞️ using HTML 🌎🖥️ Beginners

AWS Glue DynamicFrameが0レコードでスキーマが取得できない場合の対策と注意点 DevelopersIO
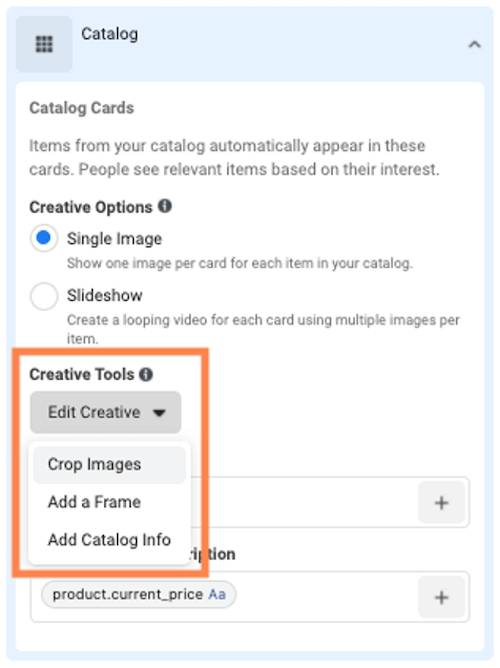
6 Ways to Customize Your Facebook Dynamic Product Ads for Maximum
# Read From The Customers Table In The Glue Data Catalog Using A Dynamic Frame Dynamicframecustomers = Gluecontext.create_Dynamic_Frame.from_Catalog(Database =.
Create_Dynamic_Frame_From_Catalog(Database, Table_Name, Redshift_Tmp_Dir, Transformation_Ctx = , Push_Down_Predicate= , Additional_Options = {}, Catalog_Id = None) Returns A.
I Have A Table In My Aws Glue Data Catalog Called 'Mytable'.
The Athena Table Is Part Of My Glue Data Catalog.
Related Post: